Collectin子接口之一:Set接口
Set接口概述:
- Set接口是Collection的子接口,Set接口没有提供额外的方法。
- Set集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set集合中,则添加操作失败。
- Set判断两个对象是否相同不是使用 == 运算符,而是根据 equals() 方法。
Set实现类之一:HashSet
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取、查找、删除性能。
HashSet 具有以下特点:
- 不能保证元素的排列顺序。
- HashSet 不是线程安全的。
- 集合元素可以是 null。
HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相
等,并且两个对象的 equals() 方法返回值也相等。
对于存放在Set容器中的对象,对应的类一定要重写equals()和hashCode(Object
obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”。
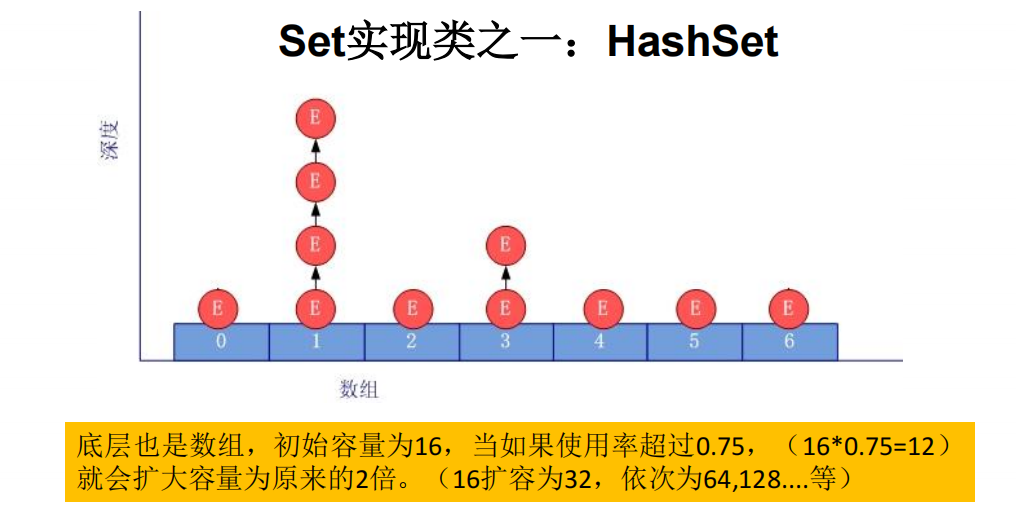
向HashSet中添加元素的过程:
当向 HashSet 集合中存入一个元素时,HashSet 会调用该对象的 hashCode() 方法来得到该对象的 hashCode 值,然后根据hashCode 值,通过某种散列函数决定该对象在 HashSet 底层数组中的存储位置。(这个散列函数会与底层数组的长度相计算得到在数组中的下标,并且这种散列函数计算还尽可能保证能均匀存储元素,越是散列分布,该散列函数设计的越好)。
如果两个元素的hashCode()值相等,会再继续调用equals方法,如果equals方法结果
为true,添加失败;如果为false,那么会保存该元素,但是该数组的位置已经有元素了,
那么会通过链表的方式继续链接。
如果两个元素的 equals() 方法返回 true,但它们的 hashCode() 返回值不相
等,hashSet 将会把它们存储在不同的位置,但依然可以添加成功。
HashSet结构图:
Set接口框架:
1 | |----Collection接口:单列集合,用来存储一个一个的对象 |
TreeSet:
1 | public class TreeSetTest { |